

Hey guys! I was staring at the Artificial Analysis Video Arena leaderboard at an embarrassing hour last week when I noticed a name I’d never seen sitting at #1 above Seedance 2.0. HappyHorse-1.0. No blog post. No founder tweet. No press release. Just a score and a horse.
Naturally, I spent the next few hours down a rabbit hole, and here’s the honest version of what creators actually need to know — scores, what they mean, and the part everyone’s glossing over: you can’t reliably access HappyHorse-1.0 right now through any official channel.
Let me show you both sides.
The Short Answer First
On blind user rankings as of early April 2026:
- No audio needed? HappyHorse-1.0 is the current #1 model.
- Need audio sync? Seedance 2.0 is still #1, by hair.
- Need to actually use something today? Seedance 2.0. Full stop.
That last point is the one this article earns its keep on. Keep reading.
Current Leaderboard Numbers
The Analysis uses blind Elo ratings — real users vote on two videos generated from the same prompt without knowing which model produced each. No lab self-reporting. No sponsored rankings. It’s one of the most trustworthy benchmarks available.
Here’s a quick reference for how Elo gaps translate to real-world differences: a 60-point gap means one model wins roughly 58–59% of head-to-head matchups. A 5-point gap is statistical noise.
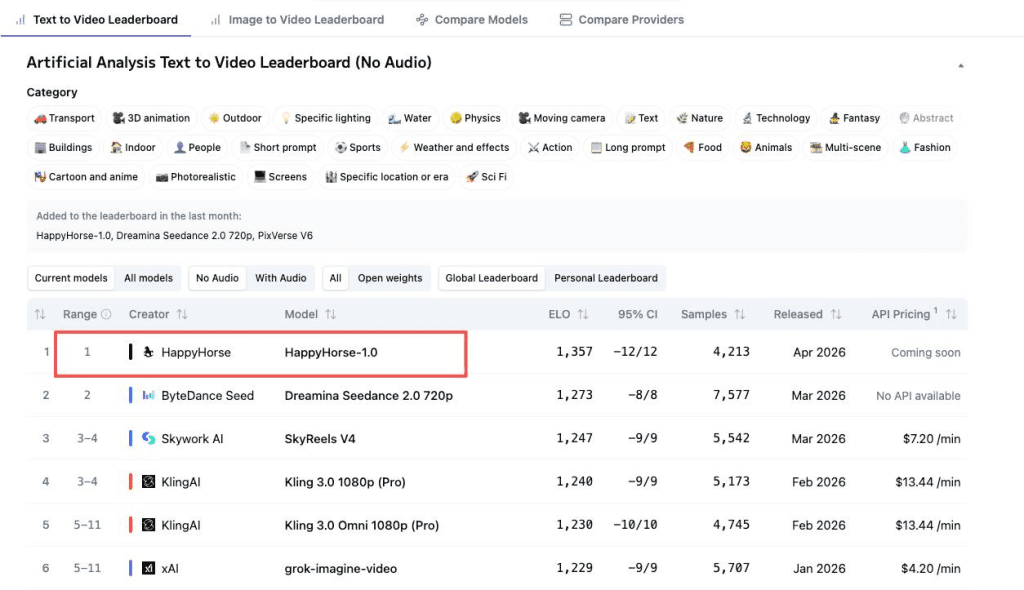
No Audio: HappyHorse #1, Seedance #2 (updated April 9 data)
| Category | HappyHorse-1.0 | Seedance 2.0 | Gap |
| Text-to-Video (no audio) | 1,357 | 1,273 | +84 — meaningful |
| Image-to-Video (no audio) | 1,402 | 1,355 | +47 — real but moderate |
That T2V gap of 84 points is not small. In blind comparisons, HappyHorse was genuinely preferred more often — cleaner motion, better prompt adherence, stronger physical realism according to community testers on X.
One important caveat I’d feel dishonest skipping: Seedance 2.0 has 7,500+ vote samples in T2V. HappyHorse’s vote count isn’t publicly broken out yet. Newer models are more volatile. These numbers will shift. Check the live leaderboard before making any decisions — don’t anchor to what this article says.
With Audio: Seedance #1, HappyHorse #2
| Category | Seedance 2.0 | HappyHorse-1.0 | Gap |
| Text-to-Video (with audio) | 1,220 | 1,215 | +5 — noise |
| Image-to-Video (with audio) | 1,158 | 1,160 | +2 — also noise |
Here’s the plot twist: the audio gap is almost nothing. A 5-point difference in T2V-with-audio isn’t a Seedance victory, it’s a dead heat. Seedance is holding the crown but barely. For I2V with audio, HappyHorse is actually fractionally ahead.
The reason Seedance 2.0 still “wins” the audio category is sample size stability, not a performance cliff. But honest answer: right now they’re essentially tied on audio quality in blind tests.
What HappyHorse Does Better
The no-audio lead is real and it comes from a few specific things:
- Visual fidelity and prompt alignment. Community testers consistently note sharper motion, better handling of physical dynamics, and stronger coherence across multi-shot sequences. The claimed architecture — a 40-layer single-stream Transformer with 8-step distilled inference — produces outputs that blind voters preferred in the majority of head-to-heads against Seedance 2.0 without audio.
- Speed. The model reportedly generates 1080p video in roughly 38 seconds on a single H100. That’s genuinely fast for this quality tier.
- Open-source licensing (in theory). The model is described as fully open-source with commercial rights — weights, distilled model, super-resolution module, inference code. If and when those actually become accessible, that’s a real differentiator for teams who want self-hosted workflows.
Where Seedance 2.0 Still Leads
- Audio synchronization, actually available: Seedance 2.0 on Dreamina is ready to use today, delivering a full workflow with built-in audio sync for music, dialogue, and ambient sound.
- Vote sample reliability: Sedance has 7,500+ blind comparisons, offering more reliable rankings than HappyHorse.
- Ecosystem maturity: CapCut/Dreamina integration, documented API behavior, known cost structure. When something goes wrong with Seedance (and sometimes it does — I’ve had it fumble complex motion prompts), I know how to work around it. With HappyHorse, there’s nothing to work around yet because there’s no real workflow to work within.
- Portrait and speech content: With 60%+ of tests focused on face-and-speech, Seedance’s stability in talking-head and lip-sync videos is more valuable than HappyHorse’s Elo score.
Access: Which One Can You Try Today
This is where the comparison gets uncomfortable — in a good, honest way.

Seedance 2.0: Available through Dreamina, with documented pricing and accessible API. You can start a project right now.
HappyHorse-1.0: When the model appeared on the Artificial Analysis leaderboard in early April 2026, it was labeled “pseudonymous” — no confirmed team, no official launch, no press release. The GitHub repo linked from various HappyHorse sites returned 404 errors at the time of writing. The Hugging Face weights weren’t downloadable. And then the model was quietly removed from the leaderboard entirely.
Third-party demo sites offer browser-based generation, but they’re not the official developer and come with their own terms.
I don’t know who built HappyHorse. Community speculation points toward Sand.ai’s daVinci-MagiHuman — the parameter count, architecture description, and language list match almost exactly — but nobody has officially confirmed anything. There’s a precedent for this kind of anonymous drop in the Chinese AI ecosystem (Pony Alpha in February 2026 turned out to be Z.ai’s GLM-5 doing a stealth stress test), but parallel patterns don’t prove identity.
What I do know: a model that wins blind benchmarks but can’t be integrated into a production workflow doesn’t change what you ship tomorrow.
Decision Guide for Creators
No audio needed → HappyHorse (when accessible)
If your project is B-roll, product visuals, abstract motion, or any video that gets audio added in post — HappyHorse-1.0 is the better model on current blind ranking data. The 84-point T2V gap is real.
But right now, “when accessible” is doing a lot of work in that sentence. Keep an eye on the official GitHub and Hugging Face repos. If weights drop publicly, this changes your workflow decision immediately.
In the meantime, the practical #1 for no-audio T2V from something you can actually run is SkyReels V4 (Elo 1,244), followed closely by Kling 3.0 Pro and PixVerse V6. Not as good as HappyHorse on benchmarks, but they exist in the real world.
Need audio sync → Seedance 2.0
For talking-head content, avatar video, lip-sync, or any workflow where audio is part of the generation — uses Seedance 2.0. The audio gap vs. HappyHorse is statistically negligible (5 points in T2V), but Seedance is accessible, stable, and has 7,500+ vote samples backing its rankings.
I’ve been using Seedance 2.0 for avatar-style videos since my Seedance 1.5 Pro review and the improvement from 1.5 to 2.0 in dynamic consistency was noticeable. It’s still my default for anything voice-driven.
Conclusion
HappyHorse-1.0 is a genuinely impressive blind-test result. An 84-point Elo lead in T2V without audio over Seedance 2.0 — which was the previous #1 — is not a fluke. Real people preferred it in blind comparisons.
But a leaderboard score you can’t reproduce in your own project doesn’t save your deadline.
Right now, Seedance 2.0 is the model that actually exists in a form creators can use. HappyHorse is the model worth watching closely — and if it drops publicly accessible weights in the next few weeks (which the open-source promises suggest it might), this comparison needs a rewrite.
I’ll update this when that happens. Until then: use what you can ship with.
FAQ
Q: What makes Seedance 2.0 better than other AI music video tools? Seedance 2.0 offers full audio sync for music, dialogue, and ambient sound, making it a complete workflow solution.
Q: Why is HappyHorse-1.0 hard to access? HappyHorse-1.0 has no public API or weights, making it unreliable and inaccessible right now.
Q: How does the voting system in the Artificial Analysis Video Arena work? Real users vote blindly on videos from the same prompt, providing a trustworthy benchmark without lab reporting or sponsorships.
Previous Posts:





