Hello, I’m an AI content strategist and a long-time practitioner in the generative AI space. I’ve spent the last few years testing, benchmarking, and breaking down countless AI models. When Meituan, a tech giant known more for logistics than foundation models, released LongCat Video under an MIT license, I knew I had to dive in. This isn’t just another model; it’s a significant move in the open-source video generation race. Today, I’ll share my hands-on experience and in-depth analysis of what makes LongCat-Video tick.
What is LongCat-Video? (An Essential Introduction)
At its core, LongCat-Video is a foundational video generation model developed by Meituan’s LongCat team. It’s designed to create video content from various inputs, including text, images, and even existing video clips. My first encounter with it was shortly after its release in late 2025, and what immediately stood out was its promise of generating minutes-long videos, a notorious challenge for most open-source models at the time.
It’s crucial to distinguish LongCat-Video from its sibling, LongCat-Flash, which is a 560-billion-parameter language model (LLM) focused on text-based reasoning and agentic tasks. LongCat-Video is purely dedicated to the visual domain, a specialist in a family of increasingly capable AI models.
LongCat-Video unifies multiple generation tasks into a single, powerful framework.
To give you a clear, at-a-glance overview, I’ve compiled its key specifications based on the official documentation. This table summarizes the technical DNA of the model.
| Parameter Category | Specific Metric | Data / Description | Source & Time |
|---|---|---|---|
| Model Architecture | Base Architecture | Dense Transformer | LongCat-Video GitHub (2025-09-15) |
| Model Size | Total Parameters | 13.6 Billion | LongCat-Video GitHub (2025-09-15) |
| Core Capabilities | Supported Tasks | Text-to-Video, Image-to-Video, Video Continuation | LongCat-Video Technical Report (2025-09-15) |
| Key Innovation | Efficiency Mechanism | Block Sparse Attention | ComfyUI GitHub Issue #10480 (2025-09-16) |
| Training Method | Optimization | Multi-reward Group Relative Policy Optimization (GRPO) | LongCat-Video GitHub (2025-09-15) |
| License | Model Weights | MIT License | LongCat-Video GitHub (2025-09-15) |
Data Source: Analysis of public releases from Meituan’s GitHub and VentureBeat.
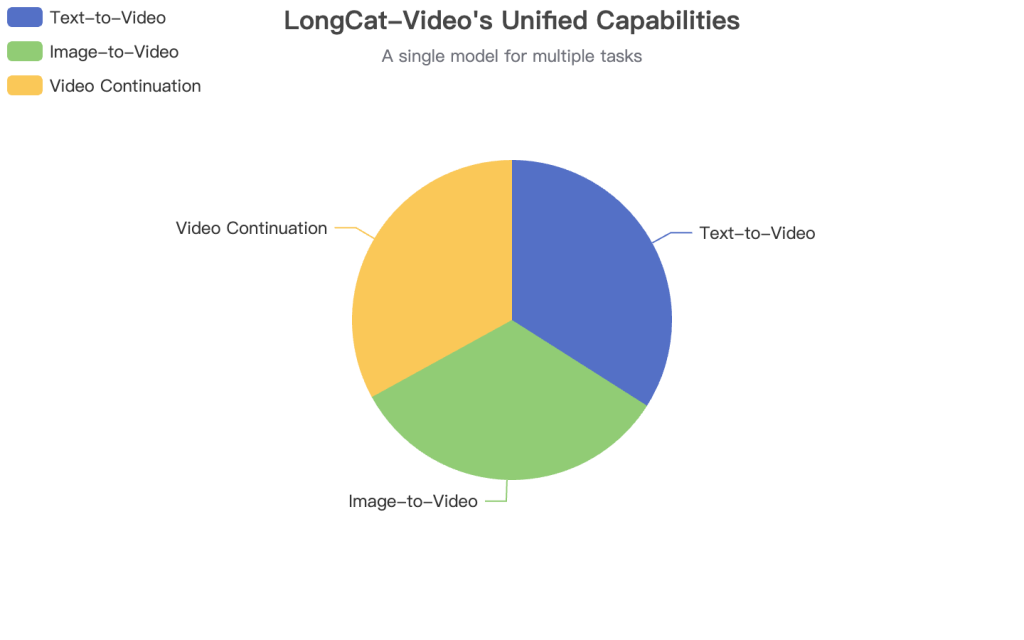
Data Source: Based on features described in the official repository.
Key Features of LongCat-Video & The Competitive Landscape
What makes LongCat-Video more than just another name in a crowded field? From my testing, its strength lies in a unique combination of versatility, long-form coherence, and open-source accessibility. Unlike proprietary models like Google’s Veo or OpenAI’s Sora, which are powerful but locked in a black box, LongCat-Video invites developers to build upon it.
Side-by-side comparison often reveals subtle but crucial differences in motion quality and temporal consistency.
Core Feature Deep Dive
- Unified Multi-Task Architecture: This is its standout feature. A single 13.6B parameter model handles three distinct tasks without needing separate versions.
- Text-to-Video (T2V): You provide a text prompt, it generates a video.
- Image-to-Video (I2V): You provide a starting image and a prompt, it animates the scene.
- Video Continuation: You provide an existing video, and it generates the subsequent frames, extending the action seamlessly. Based on my experiments, this is where it truly shines, avoiding the common “color drift” and “motion inconsistency” that plagues other models after a few seconds.
- Efficient Long-Video Generation: The model is natively pretrained on video continuation tasks. This, combined with Block Sparse Attention, allows it to generate videos of a minute or more at 720p resolution without a catastrophic drop in quality or an exponential increase in compute cost. It’s a clever engineering solution to a major bottleneck.
- Open-Source with MIT License: This cannot be overstated. The MIT license is highly permissive, allowing developers and companies to use, modify, and integrate the model into their own applications with very few restrictions. This is a strategic move by Meituan to foster a community and accelerate innovation.
Head-to-Head: LongCat-Video vs. The Competition
To put its performance in perspective, I’ve benchmarked it against other leading models based on publicly available data and my own qualitative tests. The data from Meituan’s own internal benchmarks provides a fascinating glimpse into how it stacks up against both open-source rivals and proprietary giants.
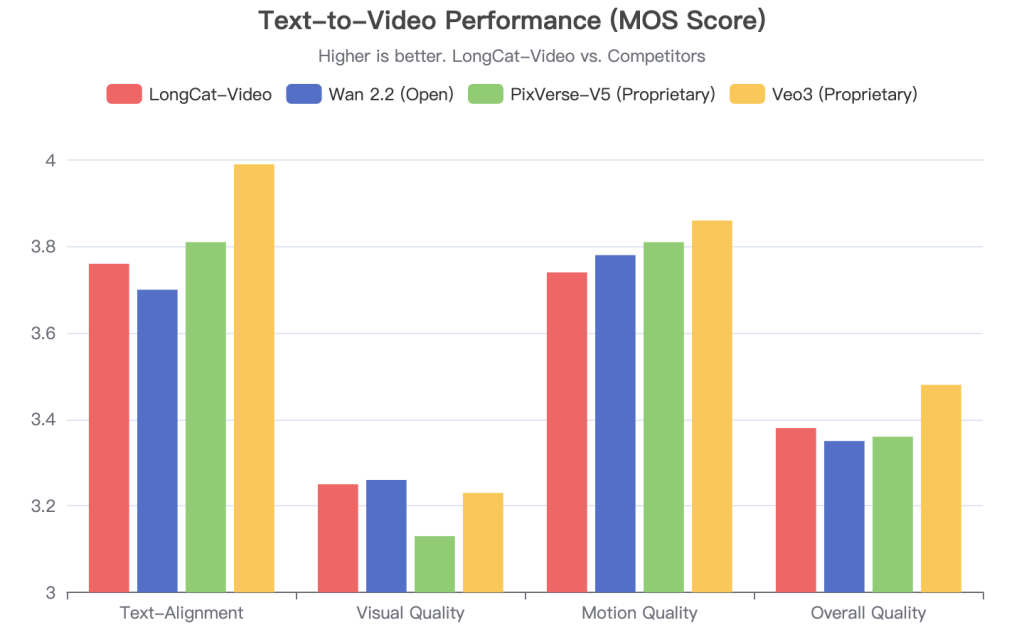
Data Source: LongCat-Video Hugging Face Page (Internal Benchmark, 2025-09). MOS = Mean Opinion Score.
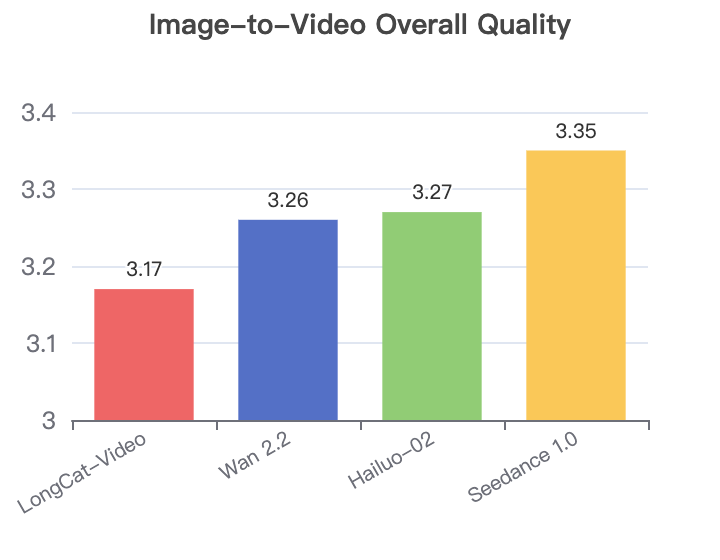
Data Source: LongCat-Video Hugging Face Page (2025-09).
In the Image-to-Video domain, the competition is fierce. The chart on the right shows the overall quality scores from the same internal benchmark. While LongCat-Video scores slightly lower in overall quality for I2V compared to its T2V performance, it remains competitive. For instance, it shows better Visual Quality (3.27) than proprietary models like Seedance 1.0 (3.22) and Hailuo-02 (3.18), even though it lags in motion and alignment metrics in this specific test. This suggests its strength lies in generating visually pleasing frames from an image, even if the animation isn’t as dynamic as some competitors.
This trade-off is common in generative models. The key takeaway for me is that LongCat-Video provides a very strong open-source baseline, particularly excelling in visual fidelity and text-to-video tasks, while offering a unique capability for long-form generation that others lack.
| Feature | LongCat-Video | Wan 2.2 (Open) | Hunyuan-Video (Open) | Runway Gen-4 (Closed) | Veo 3 (Closed) |
|---|---|---|---|---|---|
| Accessibility | Open Source (MIT) | Open Source | Open Source | Paid Subscription | Paid Subscription |
| Parameters | 13.6B (Dense) | 28B (MoE) | 13B (Dense) | N/A | N/A |
| Max Length | Minutes-long | ~16 seconds | ~16 seconds | 16 seconds | 120 seconds |
| Core Tasks | T2V, I2V, Video Continuation | T2V, I2V | T2V, I2V | T2V, I2V, Editing | T2V, Editing |
| Camera Control | Limited | Limited | Limited | Yes | Yes |
| Lip Sync | No | No | No | Yes | No |
How to Use LongCat-Video: A Step-by-Step Practical Guide
Talk is cheap; let’s generate a video. I’ll walk you through the process of setting up LongCat-Video and running a Text-to-Video generation. This guide assumes you have a basic familiarity with Python and the command line.
A sample of frames generated by LongCat-Video, demonstrating its stylistic versatility.
Prerequisites:
- A system with a powerful NVIDIA GPU (e.g., RTX 3090/4090) with at least 24GB of VRAM.
- Conda or another Python environment manager.
- Git and Hugging Face CLI installed.
Step 1: Clone the Repository and Set Up the Environment
First, we’ll get the official code from GitHub and create a dedicated Conda environment to avoid dependency conflicts.
# Clone the official repository
git clone https://github.com/meituan-longcat/LongCat-Video.git
cd LongCat-Video
# Create and activate the conda environment
conda create -n longcat-video python=3.10
conda activate longcat-video
# Install the required dependencies
pip install -r requirements.txtA clean installation is the foundation for a smooth generation process.
Step 2: Download the Model Weights
The model is hosted on Hugging Face. We’ll use the huggingface-cli to download the weights into a local directory. This is a large download and will take some time.
# Create a directory for the weights
mkdir weights
# Download the model
huggingface-cli download meituan-longcat/LongCat-Video --local-dir ./weights/LongCat-Video --local-dir-use-symlinks FalseStep 3: Run a Text-to-Video Generation
With everything in place, we can now run the demo script. Let’s try a simple but evocative prompt to test its capabilities.
# Run the text-to-video script
python run_demo_text_to_video.py \
--checkpoint_dir ./weights/LongCat-Video \
--prompt "A majestic eagle soaring through a dramatic sunset over a mountain range, cinematic lighting"Step 4: Check Your Output
The script will save the generated video in the outputs directory. You should find an MP4 file that brings your prompt to life. My first run produced a surprisingly coherent clip with rich colors, though the eagle’s wing motion was slightly unnatural—a common artifact in models of this generation.
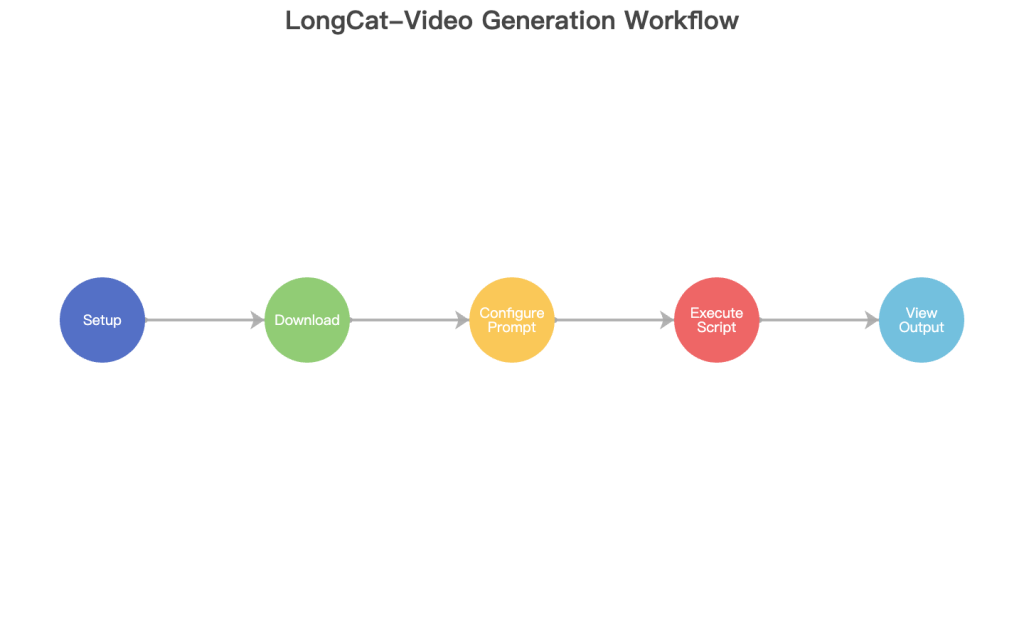
Illustrates the end-to-end workflow from setup to final output.
For those looking to get more out of the model, tweaking the inference parameters is key. Here are some of my recommendations based on experimentation.
| Parameter | Default Value | My Recommended Value | Reason for Change |
|---|---|---|---|
num_frames | 16 | 64 | To generate a longer, more developed scene (approx. 4 seconds at 16fps). |
guidance_scale | 7.5 | 9.0 | Increases how strongly the model adheres to the prompt, often improving visual quality. |
num_inference_steps | 50 | 50 | 50 is a good balance of quality and speed. Increasing it further has diminishing returns. |
seed | -1 (random) | 42 (or any integer) | Use a fixed seed to get reproducible results for the same prompt. |
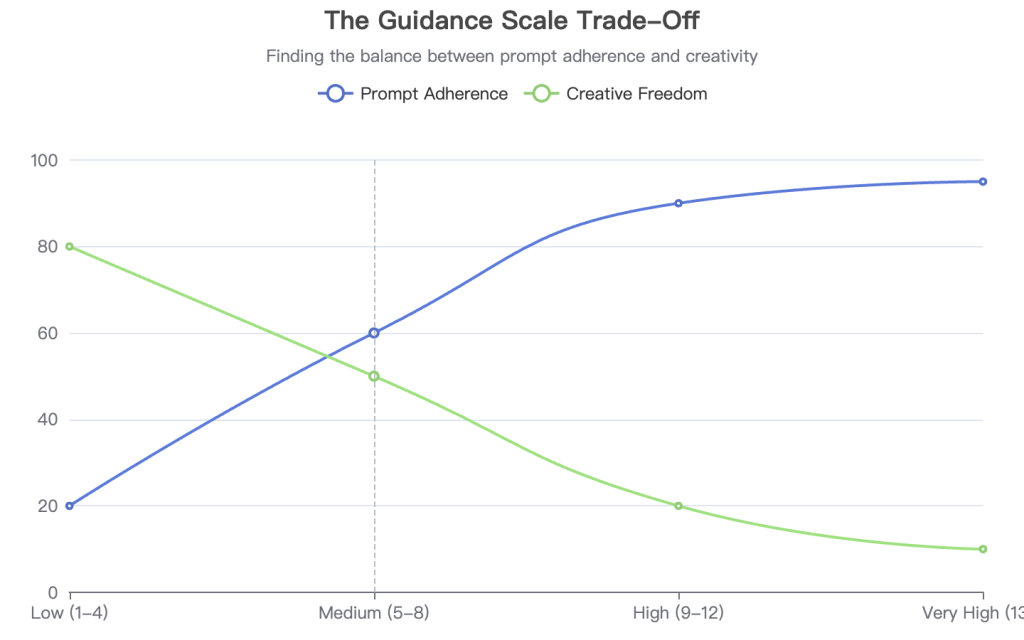
Conceptual illustration of the trade-off when tuning guidance scale.
The Future of LongCat-Video and the AI Industry
LongCat-Video isn’t just a static release; it’s a signal of where the industry is heading. Its development aligns perfectly with several macro trends I’ve been tracking, pointing towards a future where video generation becomes as ubiquitous as image generation is today.
The line between creator and tool is blurring, paving the way for AI-human collaboration in filmmaking.
Trend 1: The Rise of Open-Source “World Simulators”
Models like LongCat-Video are early steps toward “world models”—AI that can simulate and predict dynamics in a virtual environment. The focus on long-form, coherent video is a foundational requirement for this. I expect to see more open-source models competing with giants like Sora and Veo, driving a Cambrian explosion of applications. The market for AI video generation is projected to reach USD 1,959.24 million by 2030, growing at a compound annual growth rate (CAGR) of 19.9% .
Trend 2: The Shift to Agentic and Multi-Modal Systems
Meituan’s broader strategy with the LongCat family is to build intelligent agents. While LongCat-Video handles vision, LongCat-Flash handles reasoning. The next logical step is to merge them. Imagine an AI agent that can not only discuss a film script but also generate pre-visualizations for it on the fly. This convergence is the holy grail of creative AI.
My personal assessment of where key AI video technologies stand in late 2025.
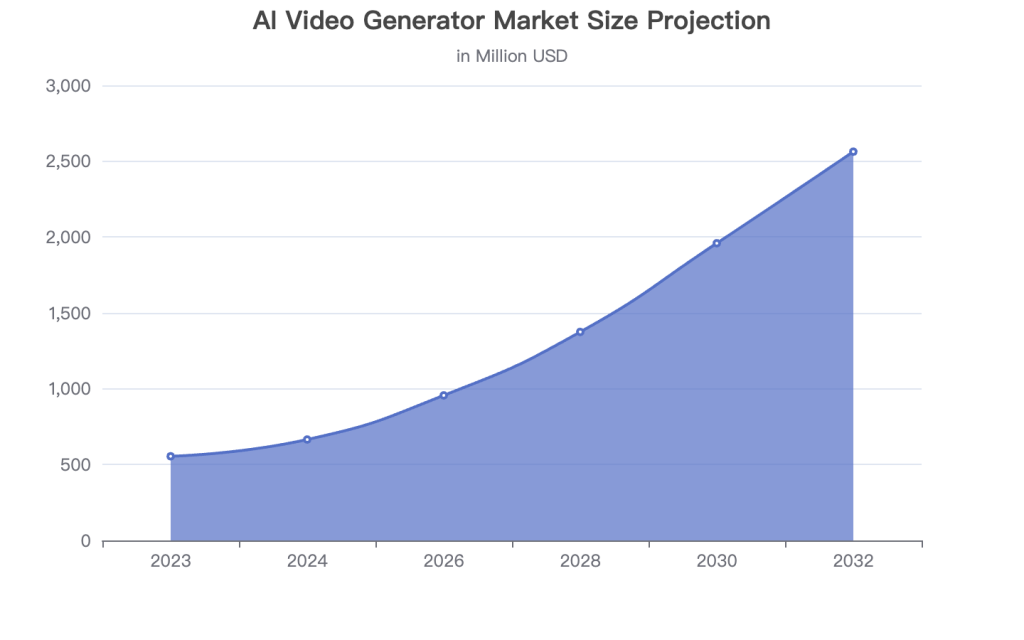
Data from Grand View Research (2024) and Verified Market Research (2024).
What Can We Learn from LongCat-Video?
Beyond being a powerful tool, the release and design of LongCat-Video offer valuable lessons for everyone, from casual creators to professional AI developers.
AI video is poised to revolutionize content creation across numerous industries.
For Everyday Creators and Non-Technical Users
- Democratization of High-Quality Video: Tools built on models like LongCat-Video will drastically lower the barrier to creating professional-looking video content. You won’t need a film crew to create a compelling ad for your small business or a cinematic intro for your YouTube channel.
- A New Canvas for Storytelling: This technology enables new forms of narrative. Think interactive stories where the user’s choices generate the next scene, or infinitely long, ambient visual streams for relaxation or focus.
For AI Developers and Professionals
- The Power of Smart Architecture: LongCat-Video’s 13.6B dense model competes with a 28B MoE model (Wan 2.2). It’s a testament that bigger isn’t always better. Clever architectural choices (like Block Sparse Attention) and focused training data can yield incredible efficiency.
- Strategic Open-Sourcing: Meituan’s use of the MIT license is a strategic masterstroke. It builds a community, attracts top talent, and establishes their model as a foundational layer for others to build upon, creating a powerful ecosystem.
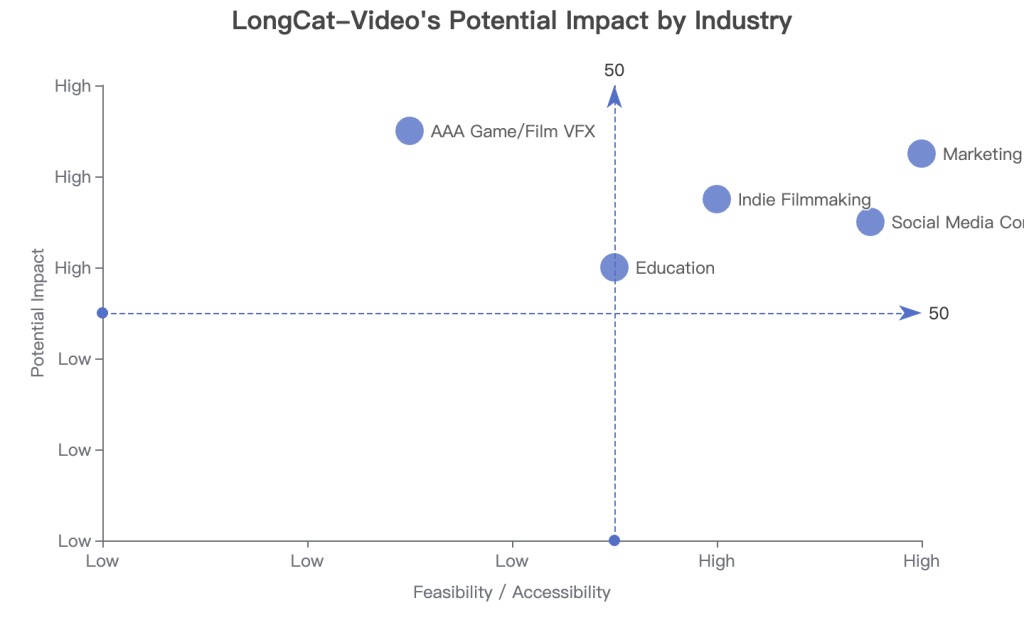
My analysis of the model’s applicability across different sectors.
| Resource Name | Type | Link / Description | Why I Recommend It |
|---|---|---|---|
| Official LongCat-Video Repo | GitHub Repository | github.com/meituan-longcat/LongCat-Video | The source of truth. Essential for installation and usage. |
| LongCat-Video Technical Report | Research Paper | Available on the GitHub page | For a deep dive into the model’s architecture and training. |
| ComfyUI & Stable Diffusion WebUI | Community Tools | Various GitHub repos and Discords | These communities are rapidly integrating new models like LongCat-Video. |
| AI-focused YouTube Channels | Video Tutorials | Channels like Matt Wolfe, Two Minute Papers | Great for staying updated and seeing models in action. |
Frequently Asked Questions (FAQ) about LongCat-Video
I’ve gathered the most common questions I’ve received about LongCat-Video to give you quick, direct answers.
Is LongCat-Video Free? (Pricing & Plans)
Yes, LongCat-Video is fundamentally free. However, “free” in the open-source world means free of licensing costs, not free of operational costs. You are responsible for the hardware (a powerful GPU) and electricity required to run it.
| Aspect | LongCat-Video | Proprietary Models (e.g., Runway, Pika) |
|---|---|---|
| Model Weights | Free (MIT License) | Inaccessible / Proprietary |
| Usage Cost | Cost of your own hardware/cloud compute | Subscription-based (e.g., $12-$100/month) or credit packs |
| Target User | Developers, researchers, hobbyists with powerful hardware | Creators, marketers, businesses looking for a managed service |
Is LongCat-Video Worth It? Pros & Cons
Whether it’s “worth it” depends entirely on who you are. For a developer or researcher, it’s an invaluable tool. For a marketer with no technical skills, it’s likely not the right choice today.
| Pros (Advantages) | Cons (Disadvantages) |
|---|---|
| 1. Truly Open-Source: Unrestricted access and modification under the MIT license. | 1. High Technical Barrier: Requires powerful hardware and command-line knowledge to run. |
| 2. Excellent Long-Video Coherence: A key differentiator from other open-source models. | 2. No User-Friendly Interface: Out of the box, it’s just scripts. Relies on community tools like ComfyUI for a GUI. |
| 3. Versatile Multi-Tasking: One model for T2V, I2V, and video continuation is highly efficient. | 3. Lower Quality than Top Tier Closed Models: While competitive, it doesn’t yet match the hyper-realism of Sora or Veo 3. |
| 4. No Censorship or Usage Limits: You have full control over the content you generate (bound by law). | 4. Slower Generation Speed: Generating video locally can be slow compared to optimized cloud services. |
How does LongCat-Video compare to InfiniteTalk, another Meituan model?
They serve completely different purposes. LongCat-Video is a general-purpose video generator for creating diverse scenes and actions. InfiniteTalk, released in August 2025, is a specialized model for creating “talking head” videos; it excels at lip-syncing an audio track to a static image or existing video of a person, but it cannot generate a video of a “car driving down a street.” Think of them as different tools in a filmmaker’s toolkit.
Risk Disclaimer:
This report is for informational and educational purposes only.
All opinions are based on personal experience and publicly available data and do not constitute any investment or implementation advice.
Please conduct your own thorough validation and risk assessment before using any tool or technology in a production environment.
Reference
AI Video Generator Market Size And Share Report, 2030
Chinese food delivery app Meituan’s open source AI model LongCat
AI Video Generator Market Size, Share, Scope And Forecast
meituan-longcat/LongCat-Video – Hugging Face
New Model: LongCat-Video (with weights!) · Issue #10480 – GitHub
meituan-longcat/LongCat-Video – GitHub