

Hey, Dora here. I check the Artificial Analysis Video Arena leaderboard most weeks — blind user votes, Elo ratings, no lab self-reporting. It’s one of the few rankings I actually trust.
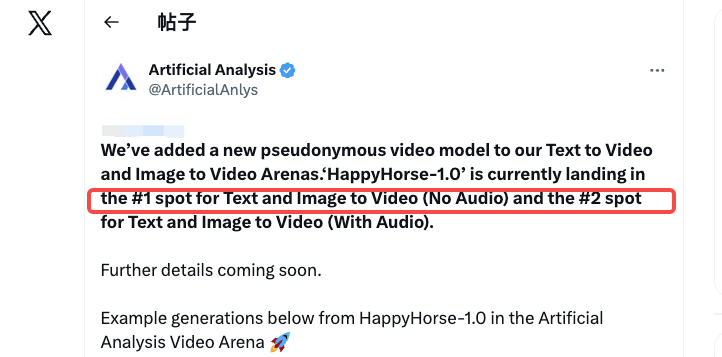
On April 7, 2026, a name I’d never seen was sitting at the top of both text-to-video and image-to-video charts. HappyHorse-1.0. No known team. No brand. GitHub and HuggingFace links that say “coming soon.”
I spent the next two days going full lab-rat mode — digging through the official site, the Artificial Analysis data, community threads on X, and a very revealing 36Kr investigation. Not sponsored, just honest results. Here’s what’s confirmed by hard data, what’s only claimed on a marketing page, and what matters if you’re actually making videos for a living.
What Is HappyHorse-1.0 in One Paragraph
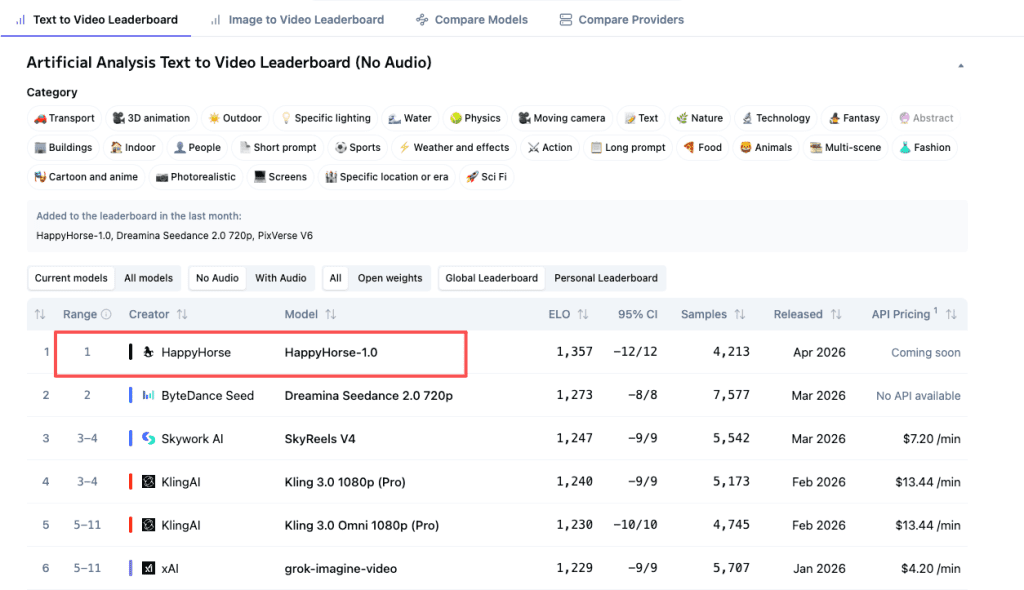
HappyHorse-1.0 is a pseudonymous AI video model that appeared on the Artificial Analysis Video Arena in early April 2026 and immediately took #1 for both text-to-video and image-to-video (no-audio). It claims joint audio-video synthesis and open-source licensing. No team has publicly claimed it — Artificial Analysis called it “pseudonymous.”
Quick answer: real enough to top a respected leaderboard, not yet real enough to integrate into any production workflow.
How It Got to #1 on the Leaderboard
This is the part built on hard evidence, not marketing copy. The Artificial Analysis Video Arena shows users blind comparisons — two videos from the same prompt, you pick which looks better. No model names visible. Elo scores come entirely from those anonymous votes.
T2V No-Audio: Elo 1333
As of April 7, 2026, HappyHorse-1.0 sits at Elo 1333 in text-to-video without audio. Dreamina Seedance 2.0 is second at 1,273. That’s a 60-point gap — which translates roughly to winning 58–59% of head-to-head blind matchups. Not a rounding error.
I2V No-Audio: Elo 1392
In image-to-video without audio, HappyHorse leads Seedance 2.0 by 37 Elo points (1,392 vs 1,355). PixVerse V6 and Grok Imagine Video follow closely behind.
With Audio: #2 Behind Seedance 2.0
The picture flips when audio is included. Seedance 2.0 edges HappyHorse out for the top spot — by 14 points in T2V with audio (Elo 1,219 vs 1,205), and by just 1 point in I2V with audio. The audio generation exists and is competitive, but it’s not leading.
One thing I need to flag — and I’m putting my nerd hat on here: Elo scores for newly added models are more volatile than established ones. Seedance 2.0 has over 7,500 vote samples in T2V. HappyHorse’s sample count isn’t broken out publicly yet. These numbers will shift. I can’t tell you which direction. I’m still collecting data on this one.
What It Can Do for Video Creators
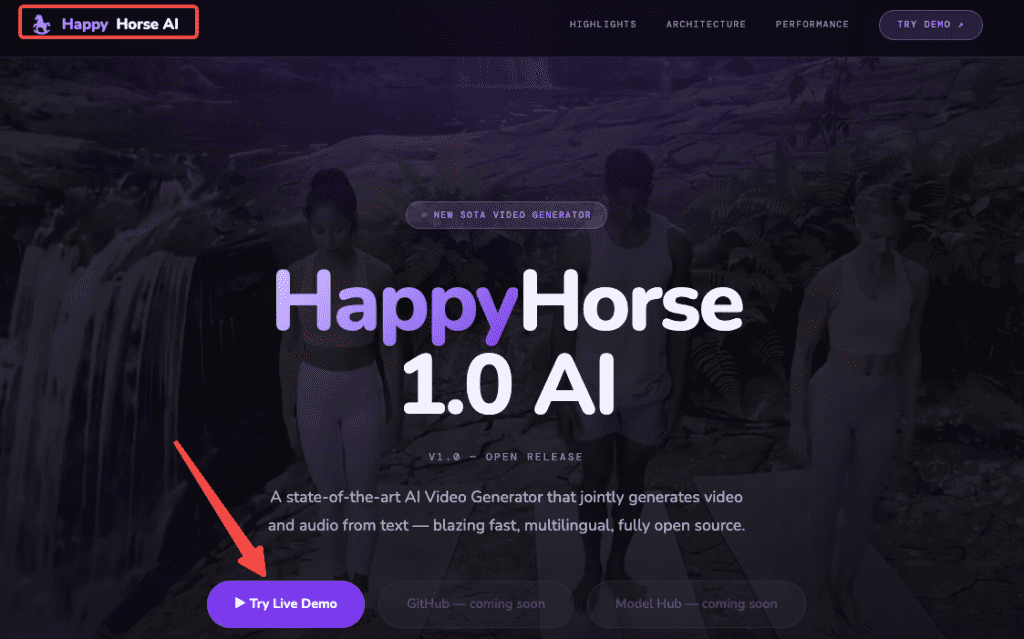
Text-to-Video
Based on arena results and community samples on X, HappyHorse-1.0 handles camera drift, body movement, and atmospheric consistency better than most top-10 models. Portrait-style clips — a single character talking, emoting, moving through a scene — seem to be its sweet spot.
Image-to-Video
The I2V Elo score is even higher than T2V, suggesting strong subject-follow capability. Upload a reference image, and it animates the scene while keeping the original composition intact. For creators who work with storyboards or product shots, that’s the use case that matters.
But here’s the part the hype doesn’t tell you: you can’t actually use it in a real pipeline right now. No public API. No downloadable weights. No documented pricing. The GitHub and Model Hub links on the official site still say “coming soon.” The leaderboard proves the outputs are good. It doesn’t prove you can access them.
Who Built It? What We Know
Pseudonymous Model — No Official Identity
Nobody has publicly claimed HappyHorse-1.0. Artificial Analysis called it “pseudonymous” when they announced it — meaning it was submitted without a verifiable team or organization attached.
The daVinci-MagiHuman Connection
This is where things get really interesting. X user Vigo Zhao ran a detailed comparison between HappyHorse-1.0’s public benchmark numbers and known models. The match was daVinci-MagiHuman — an open-source 15B-parameter video model launched on GitHub in late March 2026, jointly developed by SII-GAIR (Shanghai Innovation Institute’s AI lab, led by researcher Liu Pengfei) and Sand.ai (a Beijing-based company focused on autoregressive world models, founded by Cao Yue).
The evidence is hard to ignore: architecture descriptions match structure-for-structure, benchmark numbers align item by item, both use a single-stream Transformer for joint audio-video generation, and the supported language lists are identical. The prevailing community consensus, reported by 36Kr, is that HappyHorse is an optimized iteration of daVinci-MagiHuman submitted by Sand.ai to validate real user preferences before broader commercialization.
But I want to be careful — matching benchmarks and similar site structures are strong circumstantial evidence, not confirmation. No official statement has connected the two.
Why “HappyHorse”?
2026 is the Year of the Horse in the Chinese lunar calendar — the name is a deliberate nod. Community observers also noticed Mandarin and Cantonese listed before English on the official site, further pointing to an Asia-based origin.
What’s Not Yet Verified
Everything in this section comes from happyhorse-ai.com and third-party promotional sites. I’m flagging that upfront because none of these technical claims have been independently confirmed as of April 8, 2026. I can’t verify them myself, and I won’t pretend otherwise.
What the site claims:
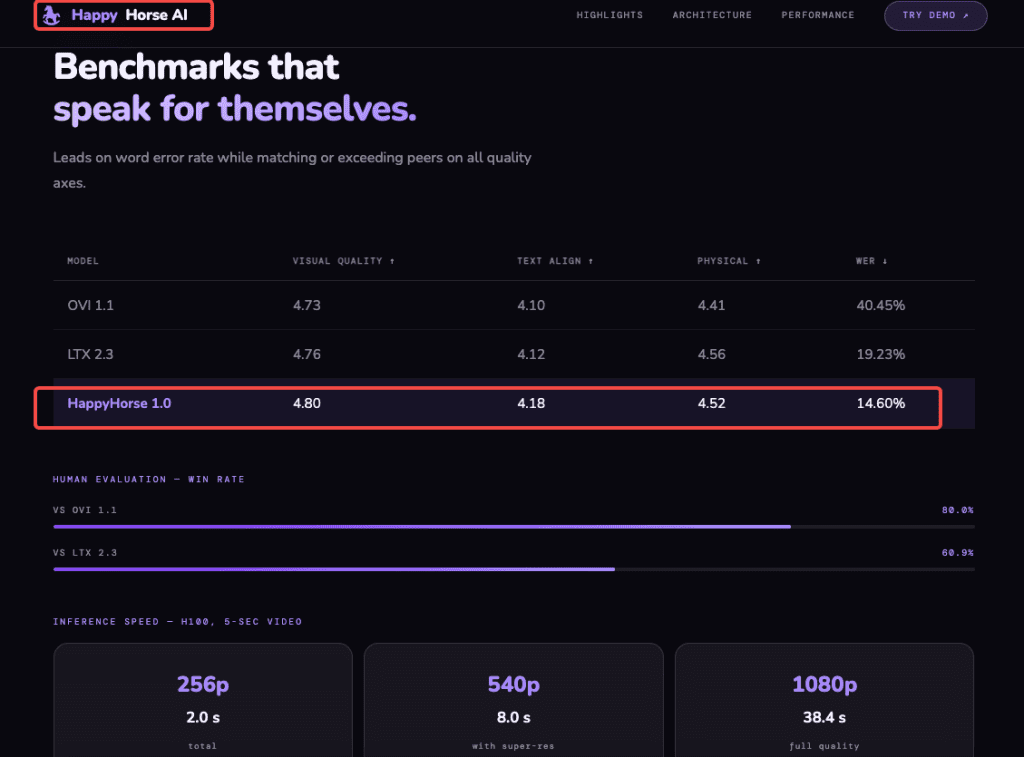
- 15B-parameter unified 40-layer self-attention Transformer
- Joint audio-video synthesis — dialogue, ambient sounds, and Foley effects in one pass
- DMD-2 distillation reducing denoising to 8 steps
- ~38 seconds for a 5-second 1080p clip on H100
- 7-language lip-sync (English, Mandarin, Cantonese, Japanese, Korean, German, French)
- Fully open source with commercial-use rights
What’s actually available right now: None of it — verifiably. GitHub says “coming soon.” HuggingFace — same. If the daVinci-MagiHuman connection holds, the architecture claims are plausible since that model’s code is public. But HappyHorse-1.0’s specific performance numbers remain self-reported.
Known caveat: some community testers who ran daVinci-MagiHuman locally found it currently requires an H100 — consumer GPUs basically won’t work. And performance is strongest in single-character portrait scenarios, with visible gaps in multi-subject and complex dynamic scenes compared to Seedance 2.0.
Is It Worth Paying Attention To?
Here’s how I’m thinking about it.
If you pick models based on output quality — the Elo data says HappyHorse-1.0 outputs consistently win blind comparisons against Seedance 2.0 and Kling 3.0. That signal is real.
If you pick models based on what you can ship with — HappyHorse doesn’t exist as a production tool yet. No API. No weights. No pricing.
If the weights actually drop — and stealth-drop-then-release has become a pattern in 2026 — a top-ranked open-source model with Apache 2.0 licensing and ~38-second 1080p generation would seriously shake things up.
My honest take: watch this one. Don’t plan around it yet. If you’re building production video workflows and need to move today, work with the tools that are actually available — and keep a tab open for HappyHorse updates.
Conclusion
HappyHorse-1.0 is the highest-ranked video model on Artificial Analysis right now, and we still don’t officially know who made it. The Elo data is solid. The daVinci-MagiHuman connection is compelling but unconfirmed. The technical claims are plausible but unverified. And the model isn’t accessible for real work yet.
The quality signal is real. Everything else needs time to shake out.
I’ll update this when things change. These models move fast.
Found something I missed? Running your own tests on daVinci-MagiHuman? Getting different results than what the leaderboard suggests? Drop it below — I read every comment. Corrections welcome. I’m not precious about being right.
FAQ
What is HappyHorse-1.0?
HappyHorse-1.0 is a pseudonymous AI video generation model that hit #1 on the Artificial Analysis Video Arena for text-to-video and image-to-video (no-audio categories) in early April 2026. No team has officially claimed it, though strong circumstantial evidence links it to the daVinci-MagiHuman open-source model developed by SII-GAIR and Sand.ai.
Can I use HappyHorse-1.0 right now?
Not in any production-ready way. As of April 8, 2026, there’s no public API, no downloadable weights, and no documented pricing. The GitHub and Model Hub links on the official site say “coming soon.”
Is HappyHorse-1.0 actually WAN 2.7?
That was an early speculation, but it doesn’t hold up well. The architecture description doesn’t match known WAN architecture, and the daVinci-MagiHuman connection is much more strongly supported by matching benchmarks, site structure, and community analysis
Previous posts:





