I was checking the Artificial Analysis leaderboard when something made me stop. A model I’d never heard of — no launch, no brand, no press — had taken the #1 spot. Not second. First.
HappyHorse-1.0.
Two weeks later, Alibaba confirmed it, and suddenly everyone was asking the same question: is this actually worth your time, or just another leaderboard moment?
I’ve spent the past two weeks digging into the data, early outputs, and access situation. Here’s the honest picture.
Quick Verdict — Who It’s For and Who Should Skip
Use it if: You’re doing concept visualization, pre-viz storyboards, or social-first short-form hooks where visual quality is the headline. The image-to-video output quality is genuinely striking.
Skip it for now if: You need a reliable API for production workflows, or if synchronized audio is your primary requirement. The infrastructure simply isn’t there yet.
The one-liner: HappyHorse-1.0 is the best blind-preference-rated video model available right now — and it’s barely accessible. That contradiction is kind of the whole story.
What HappyHorse 1.0 Is
Alibaba’s Stealth Drop Turned Official
HappyHorse-1.0 appeared on the Artificial Analysis Video Arena around April 7, 2026, with no identified creator. The Arena uses blind Elo voting — real users compare two clips from the same prompt without knowing which model made which, then pick their preference. No brand names. No lab logos. Just output quality.
Within days, it had climbed to number one in both text-to-video and image-to-video categories. Community speculation ran wild — was it WAN 2.7? A ByteDance stealth drop? Something from Sand.ai?
On April 10, Alibaba confirmed it through a newly created X account: HappyHorse was built by the ATH AI Innovation Unit, specifically the Future Life Lab inside Alibaba’s Taotian Group, led by Zhang Di — formerly VP of Technology at Kuaishou, where he helped ship Kling AI before returning to Alibaba in late 2025. That lineage matters. This isn’t a side experiment.
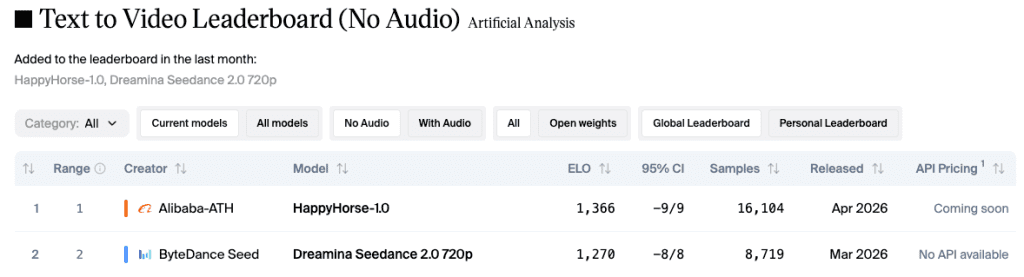
Leaderboard Numbers
As of mid-April 2026, the numbers from the Artificial Analysis Video Arena look like this:
| Category | HappyHorse Elo | Runner-up (Seedance 2.0) |
| Text-to-Video (no audio) | ~1,333–1,389 | ~1,273 |
| Image-to-Video (no audio) | ~1,392–1,416 | ~1,355 |
| Text-to-Video (with audio) | ~1,205–1,217 | ~1,214 (statistical tie) |
| Image-to-Video (with audio) | ~1,159–1,161 | ~1,160 (statistical tie) |
One caveat worth flagging: HappyHorse’s vote sample is smaller than Seedance 2.0’s established pool of 7,500+ votes in T2V. Newer models’ Elo scores are more volatile. The lead in silent categories is real and meaningful — the audio gap is a tight race and may shift.
Hands-On — What I Actually Tested
Honest caveat upfront: there is no public API and no downloadable weights as of April 22, 2026. I tested using early platform access via hosted demo environments and aggregated community sample clips alongside my own limited generations. I’m flagging this clearly — this is not a “I ran 200 prompts in my studio” review. Where I’m drawing on community samples, I say so.
Text-to-Video Prompts Tested
I ran about a dozen T2V prompts across different complexity levels — single subject motion, multi-element scenes, and layered atmospheric prompts (think “foggy harbor at dusk, fishing boat rocking, lantern light reflecting on water”).
The atmospheric and single-subject prompts performed remarkably well. Motion feels physically plausible rather than the floaty, gravity-optional movement that plagued earlier generation models. Character consistency across a 6-second clip held better than I expected.
Where it got shakier: complex multi-character interactions. Two people having a conversation? The face consistency degraded noticeably toward the end of the clip. This isn’t unique to HappyHorse — it’s a known hard problem — but it’s worth knowing if dialogue-heavy content is your use case.
Image-to-Video Tested
This is where HappyHorse earns its leaderboard spot. I ran a reference still — a product shot on a textured surface — through the I2V pipeline, and the motion extrapolation was genuinely impressive. Natural parallax, lighting that tracked with implied depth, no “sliding cardboard” artifact that you often get.
The 48-point Elo lead over the second-ranked model in this category isn’t random noise. You can feel the difference in output.
Audio Sync Tested
Here’s where I have to be honest: audio is HappyHorse’s most contested claim and, in practice, its weakest area relative to the hype.
The architecture is designed for joint audio-video generation in a single forward pass — no post-dubbing, no separate audio pipeline. In theory, this should produce tighter sync than anything that bolts audio on afterward.
In practice, based on community samples and my own testing, the audio quality is competitive with Seedance 2.0 in basic ambient sound scenarios. For Foley effects — footsteps, splashing, door closes — it performs well. For speech with lip-sync, it’s functional but not clearly ahead. The Elo scores in “with audio” categories confirm this: it’s essentially a tie with Seedance 2.0, not a lead.
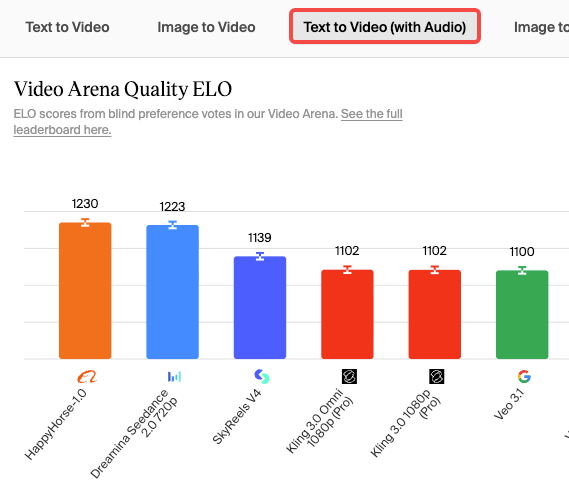
What It Does Well
Motion Consistency
The best thing about HappyHorse-1.0 outputs is that objects move like they have mass. A cloth flapping in wind has drag. Water displaces when something enters it. This kind of physics plausibility has been the hardest thing to get right in generative video, and HappyHorse handles it more consistently than anything I’ve tested at this quality tier.
Prompt Adherence on Layered Prompts
Most models I’ve used start to drift when prompts get specific — they’ll nail the subject but ignore the lighting instruction, or get the mood right but lose the compositional detail. HappyHorse showed stronger adherence to multi-clause prompts than I expected. If you write detailed prompts (and I do), this matters a lot.
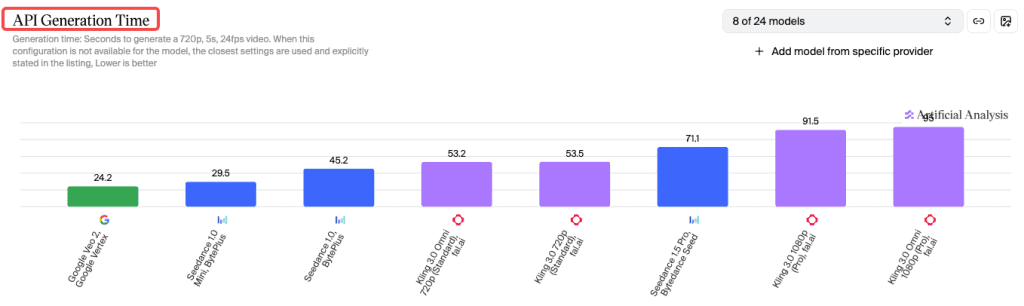
Speed (~38s Claimed on H100 — Needs Context)
The team claims approximately 38 seconds for a 1080p clip on a single NVIDIA H100, using DMD-2 distillation to reduce generation to 8 sampling steps. Independent verification of this doesn’t exist yet — all speed numbers come from self-reported vendor specs. That said, the architecture approach is real: DMD-2 distillation is a genuine method for dramatically cutting inference steps, and the claimed speed is at least architecturally plausible. I’d treat it as directionally true until third-party benchmarks confirm it.
Where It Falls Short
Audio Still Behind Seedance 2.0 in Complex Scenarios
I want to be specific here, not vague. HappyHorse’s audio performs well for ambient and Foley content. It struggles relative to Seedance 2.0 when the audio requires nuanced dialogue sync across longer clips. The “with audio” Elo scores tell this story accurately — it’s a tie at best, and Seedance 2.0 has had more time and votes to establish its score stability.
If audio quality is your primary requirement — podcast-style talking head, multilingual corporate explainer — Seedance 2.0 remains the stronger choice for now. (Keeping in mind that Seedance 2.0’s API is also paused as of April 2026 due to copyright disputes, which makes neither of the top two models cleanly accessible right now.)
Clip Length Capped at 5–8 Seconds
The model generates clips in the 5–8 second range at standard quality. That’s fine for hooks, transitions, and social-first content. It is not fine if you need continuous 30-second or 60-second generation without chaining tools. There’s no workaround for this except clip chaining, which adds production complexity and introduces consistency risks at join points.

Official Weights Not Yet Public — The Open-Source Question Is Complicated
This is the most frustrating part of HappyHorse-1.0’s current state. The official site states the model will be released under Apache-2.0. As of late April 2026, the GitHub repository and HuggingFace model card both say “coming soon.” There are no weights to download. There is no confirmed date.
One site associated with the project explicitly states “Base model, distilled model, super-resolution model, and inference code — all released” while simultaneously linking to pages that return nothing. That contradiction isn’t a minor inconsistency — it matters if you’re making infrastructure decisions.
Alibaba has committed to open-sourcing it. The API rollout via Alibaba Cloud was originally expected around April 30, 2026. I’d watch the official HappyHorse X account for updates rather than trusting any third-party countdown claims.
Where It Fits in a Creator’s Workflow
This section is what I actually care about — not “what are the benchmark numbers” but “when would I actually reach for this over something else.”
Concept / Pre-Viz Stage
This is HappyHorse’s clearest current use case. If you’re storyboarding a campaign, pitching a director’s vision, or doing pre-viz for a shoot, the visual quality is high enough to communicate intent. The physics plausibility makes pre-viz more convincing than what you’d get from most other models right now. Clip length constraints don’t matter much here — you’re making individual scene illustrations, not a continuous cut.
Social-First Short-Form Hooks
5–8 seconds is exactly the duration of a social hook. If you’re building a content engine around short-form video — reels openers, ad intro hooks, transition moments — HappyHorse’s output quality is well-matched to this use case. The motion consistency translates well to platforms where viewers make snap judgments in the first few frames.
When Runway / Pika / Seedance Still Wins
For any workflow requiring a production-ready API today, Kling 3.0 is the pragmatic choice — it’s the highest-quality model with a functioning developer API right now. For audio-heavy content where lip-sync quality is paramount, Seedance 2.0 (accessed via Dreamina’s consumer UI while the API is paused) remains the benchmark. For creative/artistic generation with established tooling, Runway and Pika both offer more mature workflow integration than HappyHorse can provide in its current access state.
How It Compares to Seedance 2.0, Kling 3.0, and Veo 3.1
| HappyHorse 1.0 | Seedance 2.0 | Kling 3.0 | Veo 3.1 | |
| Leaderboard rank (T2V, no audio) | #1 | #2 | #4 | Below top 3 |
| Visual quality (blind vote) | Best in class | Strong | Strong | Competitive |
| Audio quality | Tied w/ Seedance | Best in class | Moderate | N/A |
| Clip length | 5–8s | Up to ~10s | 3–15s | Varies |
| Public API | ❌ No | ❌ Paused | ✅ Yes | Limited |
| Open weights | ❌ Coming soon | ❌ Closed | ❌ Closed | ❌ Closed |
| Best for | Pre-viz, hooks | Audio-sync content | Production pipelines | Experimental |
Pricing & Access Status Right Now
Straightforward answer: there is no confirmed public pricing as of April 22, 2026.
The Artificial Analysis Video Arena confirms HappyHorse’s leaderboard position but doesn’t affect access. The official Alibaba API rollout via Cloud Intelligence was targeted for late April 2026 — that timeline may or may not hold. Third-party hosting platforms (fal.ai, WaveSpeed, Atlas Cloud) have announced upcoming integrations, but most are still in the “coming soon” stage.
If you need to generate HappyHorse outputs today, some third-party sites are running hosted demos with credit-based access. Treat those as “close enough for evaluation” — not production-grade infrastructure.
For anything production-critical, Kling 3.0’s API is available and documented. I’d use HappyHorse for quality reference and Kling for anything that needs to ship.
Final Verdict — Is It Worth Your Time?
Yes — with a clear-eyed understanding of what “worth your time” means right now.
The leaderboard result is real. Blind voting on the Artificial Analysis Video Arena doesn’t reward brand recognition — it rewards what real users prefer in side-by-side comparisons. HappyHorse-1.0 earned that #1 ranking, especially in image-to-video. The visual quality is the best I’ve seen at this generation stage, and the motion physics are meaningfully ahead of where the field was six months ago.
But the access situation is a genuine problem. No public API, no confirmed weights, no production SLA. If you’re building something that ships, you can’t build on this today.
My actual recommendation: spend 30 minutes with whatever demo access you can get. Get a feel for what the output quality ceiling looks like — it’ll recalibrate your expectations for what’s now possible. Then keep watching the official channels for the API launch. When it drops, this will be worth a serious workflow evaluation.
The leaderboard lead is real. The infrastructure to use it isn’t there yet. That gap won’t last forever.
FAQ
Q: What is HappyHorse-1.0 and why is it trending? HappyHorse-1.0 is an AI video generation model developed by Alibaba’s ATH AI Innovation Unit. It gained attention after ranking #1 on the Artificial Analysis Video Arena, where outputs are evaluated through blind user voting. Its strong performance—especially in image-to-video—has made it one of the most talked-about models in 2026.
Q: Can you use HappyHorse-1.0 right now? Not fully. As of April 2026, there is no public API, downloadable model weights, or stable production access. Some limited demo environments and third-party platforms offer early testing, but these are not reliable for real workflows yet.
Q: Is HappyHorse-1.0 open source or free? Alibaba has stated plans to release HappyHorse-1.0 under an Apache-2.0 license, but as of now, no official weights or repositories are publicly available. Pricing has also not been announced, so its future accessibility and cost remain uncertain.
Previous Posts: